 |
| [Image source] |
Let's first review how this problem is tackled in a sequential setting - then we'll proceed with a distributed map-reduce solution.
Reservoir sampling
One of the most common sequential approaches to this problem is the so-called reservoir sampling. The algorithm works as follows: the data is coming through a stream and the solution keeps a vector of $k$ elements (the reservoir) initialized with the first $k$ elements in the stream and incrementally updated as follows: when the $i$-th element arrives (with $i \gt k$), pick a random integer $r$ in the interval $[1,..,i]$, and if $r$ happens to be in the interval $[1,..,k]$, replace the $r$-th element in the solution with the current element.A simple implementation in Python is the following. The input items are the lines coming from the standard input:
# reservoir_sampling.py
import sys, random
k = int(sys.argv[1])
S, c = [], 0
for x in sys.stdin:
if c < k: S.append(x)
else:
r = random.randint(0,c-1)
if r < k: S[r] = x
c += 1
print ''.join(S),
for i in {1..100}; do echo $i; done | python ./reservoir_sampling.py 3Why does it work? The math behind it(*)
(Feel free to skip this section if math and probability are not your friends)Let's convince ourselves that every element belongs to the final solution with the same probability.
Let $x_i$ be the $i$-th element and $S_i$ be the solution obtained after examining the first $i$ elements. We will show that $\Pr[x_j \in S_i] = k/i$ for all $j\le i$ with $k\le i\le n$. This will imply that the probability that any element is in the final solution $S_n$ is exactly $k/n$.
The proof is by induction on $i$: the base case $i=k$ is clearly true since the first $k$ elements are in the solution with probability exactly 1. Now let's say we're looking at the $i$-th element for some $i>k$. We know that this element will enter the solution $S_i$ with probability exactly $k/i$. On the other hand, for any of the elements $j\lt i$, we know that it will be in $S_i$ only if it was in $S_{i-1}$ and is not kicked out by the $i$-th element. By induction hypothesis, $\Pr[x_j \in S_{i-1}]= k/(i-1)$, whereas the probability that $x_j$ is not kicked out by the current element is $(1-1/i) = (i-1)/i$. We can conclude that $\Pr[x_j \in S_{i}] = \frac{k}{i-1}\cdot\frac{i-1}{i} = \frac{k}{i}$.
MapReduce solution
How do we move from a sequential solution to a distributed solution?To make the problem more concrete, let's say we have a number of files where each line is one of the input elements (the number of lines over all files sum up to n) and we'd like to select exactly k of those lines.
The Naive solution
The simplest solution is to reduce the distributed problem to a sequential problem by using a single reducer and have every mapper map every line to that reducer. Then the reducer can apply the reservoir sampling algorithm to the data. The problem with this approach though is that the amount of data sent by the mappers to the reducer is the whole dataset.A better approach
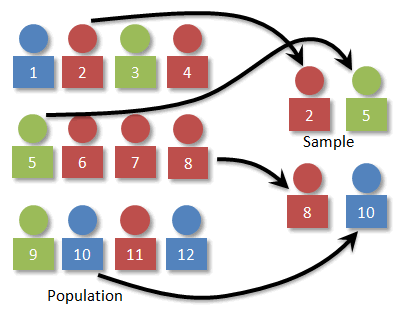
The core insight behind reservoir sampling is that picking a random sample of size $k$ is equivalent to generating a random permutation (ordering) of the elements and picking the top $k$ elements. Indeed, a random sample can be generated as follows: associate a random float id with each element and pick the elements with the $k$ largest ids. Since the ids induce a random ordering of the elements (assuming the ids are distinct), it is clear that the elements associated with the $k$ largest ids form a random subset.We will start implementing this new algorithm in a streaming sequential setting. The goal here is to incrementally keep track of the $k$ elements with largest ids seen so far. A useful data structure that can be used to this goal is the binary min-heap. We can use it as follows: we initialize the heap with the first $k$ elements, each associated with a random id. Then, when a new element comes, we associate a random id with it: if its id is larger than the smallest id in the heap (the heap's root), we replace the heap's root with this new element.
A simple implementation in Python is the following:
# rand_subset_seq.py
import sys, random
from heapq import heappush, heapreplace
k = int(sys.argv[1])
H = []
for x in sys.stdin:
r = random.random() # this is the id
if len(H) < k: heappush(H, (r, x))
elif r > H[0][0]: heapreplace(H, (r, x)) # H[0] is the root of the heap, H[0][0] its id
print ''.join([x for (r,x) in H]),
for i in {1..100}; do echo $i; done | python ./rand_subset_seq.py 3An important trick that we can use is the fact that Hadoop framework will automatically present the values to the reducer in order of keys from lowest to highest. Therefore, by using the negation of the id as key, the first $k$ element read by the reducer will be the top $k$ elements we are looking for.
We now provide the mapper and reducer code in Python language, to be used with Hadoop streaming.
The following is the code for the mapper:
#!/usr/bin/python
# rand_subset_m.py
import sys, random
from heapq import heappush, heapreplace
k = int(sys.argv[1])
H = []
for x in sys.stdin:
r = random.random()
if len(H) < k: heappush(H, (r, x))
elif r > H[0][0]: heapreplace(H, (r, x))
for (r, x) in H:
# by negating the id, the reducer receives the elements from highest to lowest
print '%f\t%s' % (-r, x),
#!/usr/bin/python
# rand_subset_r.py
import sys
k = int(sys.argv[1])
c = 0
for line in sys.stdin:
(r, x) = line.split('\t', 1)
print x,
c += 1
if c == k: break
chmod +x ./rand_subset_m.py and chmod +x ./rand_subset_r.py). Then we pipe the data to the mapper, sort the mapper output, and pipe it to the reducer.
k=3; for i in {1..100}; do echo $i; done | ./rand_subset_m.py $k | sort -k1,1n | ./rand_subset_r.py $kRunning the Hadoop job
We can finally run our Python MapReduce job with Hadoop. If you don't have Hadoop installed, you can easily set it up on your machine following these steps. We leverage Hadoop Streaming to pass the data between our Map and Reduce phases via standard input and output. Run the following command, replacing [myinput] and [myoutput] with your desired locations. Here, we assume that the environment variable HADOOP_INSTALL refers to the Hadoop installation directory.k=10 # set k to what you need
hadoop jar ${HADOOP_INSTALL}/contrib/streaming/hadoop-*streaming*.jar \
-D mapred.reduce.tasks=1 \
-D mapred.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \
-D mapred.text.key.comparator.options=-n \
-file ./rand_subset_m.py -mapper "./rand_subset_m.py $k" \
-file ./rand_subset_r.py -reducer "./rand_subset_r.py $k" \
-input [myinput] -output [myoutput]Further notes
The algorithm-savvy reader has probably noticed that while reservoir sampling takes linear time to complete (as every step takes constant time), the same cannot be said of the approach that uses the heap. Each heap operation takes $O(\log k)$ time, so a trivial bound for the overall running time would be $O(n \log k)$. However, this bound can be improved as the heap replace operation is only executed when the $i$-th element is larger than the root of the heap. This happens only if the $i$-th element is one of the $k$ largest elements among the first $i$ elements, which happens with probability $k/i$. Therefore the expected number of heap replacements is $\sum_{i=k+1}^n k/i \approx k \log(n/k)$. The overall time complexity is then $O(n + k\log(n/k)\log k)$, which is substantially linear in $n$ unless $k$ is comparable to $n$.What if the sample doesn't fit into memory?
So far we worked under the assumption that the desired sample would fit into memory. While this is usually the case, there are scenarios in which the assumption may not hold. Afterall, in the big data world, 1% of a huge dataset may still be too much to keep in memory!A simple solution to generate large samples is to modify the mapper to simply output every item along with a random id as key. The MapReduce framework will sort the items by id (substantially, generating a random permutation of the elements). The (single) reducer can be left as is to just pick the first $k$ elements. The drawback with this approach is again that the whole dataset needs to be sent to a single reducer. Moreover, even if the reducer does not store the $k$ items in memory, it has to go through them, which can be time-consuming if $k$ is very large (say $k=n/2$).
We now discuss a different approach that uses multiple reducers. The key idea is the following: suppose we have $\ell$ buckets and generate a random ordering of the elements first by putting each element in a random bucket and then by generating a random ordering in each bucket. The elements in the first bucket are considered smaller (with respect to the ordering) than the elements in the second bucket and so on. Then, if we want to pick a sample of size $k$, we can collect all of the elements in the first $j$ buckets if they overall contain a number of elements $t$ less than $k$, and then pick the remaining $k-t$ elements from the next bucket. Here $\ell$ is a parameter such that $n/\ell$ elements fit into memory. Note the key aspect that buckets can be processed distributedly.
The implementation is as follows: mappers associate with each element an id $(j,r)$ where $j$ is a random index in $\{1,2,\ldots,\ell\}$ to be used as key, and $r$ is a random float for secondary sorting. In addition, mappers keep track of the number of elements with key less than $j$ (for $1\le j\le \ell$) and transmit this information to the reducers. The reducer associated with some key (bucket) $j$ acts as follows: if the number of elements with key less or equal than $j$ is less or equal than $k$ then output all elements in bucket $j$; otherwise, if the number of elements with key strictly less than $j$ is $t\lt k$, then run a reservoir sampling to pick $k-t$ random elements from the bucket; in the remaining case, that is when the number of elements with key strictly less than $j$ is at least $k$, don't output anything.
After outputting the elements, the mapper sends the relevant counts to each reducer, using -1 as secondary key so that this info is presented to the reducer first.
#!/usr/bin/python
# rand_large_subset_m.py
import sys, random
l = int(sys.argv[1])
S = [0 for j in range(l)]
for x in sys.stdin:
(j,r) = (random.randint(0,l-1), random.random())
S[j] += 1
print '%d\t%f\t%s' % (j, r, x),
for j in range(l): # compute partial sums
prev = 0 if j == 0 else S[j-1]
S[j] += prev # number of elements with key less than j
print '%d\t-1\t%d\t%d' % (j, prev, S[j]) # secondary key is -1 so reducer gets this first
#!/usr/bin/python
# rand_large_subset_r.py
import sys, random
k = int(sys.argv[1])
line = sys.stdin.readline()
while line:
# Aggregate Mappers information
less_count, upto_count = 0, 0
(j, r, x) = line.split('\t', 2)
while float(r) == -1:
l, u = x.split('\t', 1)
less_count, upto_count = less_count + int(l), upto_count + int(u)
(j, r, x) = sys.stdin.readline().split('\t', 2)
n = upto_count - less_count # elements in bucket j
# Proceed with one of the three cases
if upto_count <= k: # in this case output the whole bucket
print x,
for i in range(n-1):
(j, r, x) = sys.stdin.readline().split('\t', 2)
print x,
elif less_count >= k: # in this case do not output anything
for i in range(n-1):
line = sys.stdin.readline()
else: # run reservoir sampling picking (k-less_count) elements
k = k - less_count
S = [x]
for i in range(1,n):
(j, r, x) = sys.stdin.readline().split('\t', 2)
if i < k:
S.append(x)
else:
r = random.randint(0,i-1)
if r < k: S[r] = x
print ''.join(S),
line = sys.stdin.readline()
l=10; k=50; for i in {1..100}; do echo $i; done | ./rand_large_subset_m.py $l | sort -k1,2n | ./rand_large_subset_r.py $kRunning the Hadoop job
Again, we're assuming you have Hadoop ready to crunch data (if not, follow these steps). To run our Python MapReduce job with Hadoop, run the following command, replacing [myinput] and [myoutput] with your desired locations.k=100000 # set k to what you need
l=50 # set the number of "buckets"
r=16 # set the number of "reducers" (depends on your cluster)
hadoop jar ${HADOOP_INSTALL}/contrib/streaming/hadoop-*streaming*.jar \
-D mapred.reduce.tasks=$r \
-D mapred.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \
-D stream.num.map.output.key.fields=2 \
-D mapred.text.key.partitioner.options=-k1,1 \
-D mapred.text.key.comparator.options="-k1n -k2n" \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
-file ./rand_large_subset_m.py -mapper "./rand_large_subset_m.py $l" \
-file ./rand_large_subset_r.py -reducer "./rand_large_subset_r.py $k" \
-input [myinput] -output [myoutput]stream.num.map.output.key.fields sets the key to be the pair $(j, r)$. We use mapred.text.key.partitioner.options along with the -partitioner argument to partition only over $j$. Finally, we use mapred.text.key.comparator.options along with mapred.output.key.comparator.class to sort by $j$ in numerical order and then by $r$ again in numerical order.


I think your implementation of reservoir sampling is not correct. In line 11 the randint should be inclusive c. If you take k=1 and only 2 samples, then the end result would always be the 2nd sample. You can also test it by running the sampler many times and check that all input samples have equal chance. You will see that the first k items in the sequence have less chance to be picked. If the randint is inclusive c everything is fine.
ReplyDeleteThe index is 0-based.
DeleteEven with zero-based indexing, it has to be inclusive c. Try it out for yourself by letting k=2 and using an input of 2 lines. The output will always be the second line. (Yes, I've tested this on your code.) So:
DeleteThis
r = random.randint(0,c-1)
Should be
r = random.randint(0,c)
Other than that, great work!
Hello there,
ReplyDeleteI'm glad you appreciated my image as a nice way to represent random sampling. Could you please site it? I use the CC BY-NC-SA 3.0 license on all my works, so you're free to use it as long as you cite the original source. It was originally hosted here: http://faculty.elgin.edu/dkernler/statistics/ch01/1-3.html.
Thanks,
Dan Kernler
Thanks for the image Dan, I added a link to the original source.
DeleteFortunately, Apache Hadoop is a tailor-made solution that delivers on both counts, by turning big data insights into actionable business enhancements for long-term success. To know more, visit Big data Training Bangalore
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteWow amazing i saw the article with execution models you had posted for the mapreduce concept with the Hadoop. It was such informative. Really its a wonderful article. Thank you for sharing and please keep update like this type of article because i want to learn more relevant to this topic.
ReplyDeleteSAS Training in Chennai
This comment has been removed by the author.
ReplyDeleteI just see the post i am so happy the post of information's.So I have really enjoyed and reading your blogs for these posts.Any way I’ll be subscribing to your feed and I hope you post again soon.
ReplyDeletedigital marketing course in chennai
Your thinking toward the respective issue is awesome also the idea behind the blog is very interesting which would bring a new evolution in respective field. Thanks for sharing.
ReplyDeleteHome Spa Services in Mumbai
Very nice post here and thanks for it .I always like and such a super contents of these post.Excellent and very cool idea and great content of different kinds of the valuable information's.
ReplyDeleteSat Coaching Chennai
Very help full article on Hadoop for Beginner.
ReplyDeleteHadoop technology has a huge demand in IT Industry.
http://eonlinetraining.co/course/big-data-hadoop-online-training/
It's interesting that many of the bloggers to helped clarify a few things for me as well as giving.Most of ideas can be nice content.The people to give them a good shake to get your point and across the command.
ReplyDeleteHadoop Training in Chennai
Superb explanation & it's too clear to understand the concept as well, keep sharing admin with some updated information with right examples.Keep update more posts.
ReplyDeleteDigital Marketing Training in Chennai
Hadoop Training in Chennai
Thanks for sharing amazing contenthadoop online training in hyderabad
ReplyDeleteWhat you have written in this post is exactly what I have experience when I first started my blog.I’m happy that I came across with your site this article is on point,thanks again and have a great day.Keep update more information.
ReplyDeleteDigital Marketing Training in Chennai
Hadoop Training in Chennai
Best Web design company in Hyderabad
ReplyDeleteiOS App development company in Hyderabad
Really, these quotes are the holistic approach towards mindfulness. In fact, all of your posts are. Proudly saying I’m getting fruitfulness out of it what you write and share. Thank you so much to both of you.
ReplyDeleteSharepoint Training in Chennai
Web Designing Training in Chennai
Good one...Awesome blog
ReplyDeleteonline pickles in hyderabad
Snacks and pickles online
Study MBBS in Philippines
Low cost MBBS in Philippines
Really nice information here about by choosing with the headlines. We want to make the readers whether it is relevant for their searches or not. They will decide by looking at the headline itself. I agree with your points but i can't understand what's logic behind by including with the number? Why most of the marketers will suggest that one? Is there any important factor within that please convey me.....
ReplyDeleteVMWare Training in Chennai
MSBI Training in Chennai
Thanks for providing valuable information.It saves our time to search..keep update with your blogs..once check it out Big Data Hadoop Online Training Hyderabad
ReplyDeleteBig Data Hadoop Online Training
Great article,thank u for sharing interesting concept...
ReplyDeleteHadoop Training in Chennai
ReplyDeleteThanks for sharing such a great information..Its really nice and informative.
Turnkey Home Interiors Chennai
Thanks For Sharing such a good post. Keep sharing...
ReplyDeleteBig Data Online Training Hyderabad
Check it once through Hadoop admin Online Training for more info.
ReplyDeleteNice Information One Can also Check other sources to opt for best choice.
ReplyDeleteHadoop Admin Online Training
Microsoft Dynamics CRM Online Training
Revanth Technologies is a vast experienced online training center in Hyderabad, India since 2006, with highly qualified and real time experienced faculties, offers Python online training with real time project scenarios.
ReplyDeleteIn the course training we are covering Types and Operations,Statements and Syntax,Functions,Modules,Classes and OOP, Exceptions and Tools etc..
For more details please contact: 9290971883
Mail id: revanthonlinetraining@gmail.com
For course content and more details please visit
http://www.revanthtechnologies.com/python-online-training-from-india.php
Hi I have heard about this Reservoir Sampling in MapReduce which comes in Hadoop. Sampling the data into different segments and workingout on different platforms will give the compressed data in and around the subset of elements When I was having my PMP Training in Kuwait I was supposed to get into different examples of hadoop also As it is having the best outcome in the market Hadoop trainers give their examples using this type of sampling Anywayz Nice blog and I hope for more updates from you Thankyou
ReplyDeletewonderful post and very helpful, thanks for all this information. You are including better information regarding this topic in an effective way.Thank you so much
ReplyDeleteWeb Design Company in Chennai
Reservoir Sampling is one of the best technology and Sequential approach for solving the problem. The way you Explaining about it is Really Fantastic... Thank you Very Much... Hope you come with more articles like Microsoft Dynamics CRM . Thanks In Advance
ReplyDeleteIt's my pleasure see a blog like this in a real time of blog world-:)
ReplyDeleteSAP ABAP Training in Chennai
SAP MM Training in Chennai
SAP HR Training in Chennai
Artcile was simply superb Hadoop Admin Online Training Hyderabad
ReplyDeleteIt's really very nice to read.... Thanks for sharing this usefull article....
ReplyDeleteAndroid Course
Wow.That's great blog to read about Hadoop technology.
ReplyDeleteInterior Designers in Chennai
Interiors in Chennai
Good Interior Designers in Chennai
It's really useful to new technology learners.I Greeting to you...
ReplyDeleteInterior Designers in Chennai
Interior Decorators in Chennai
Interior Design in Chennai
This helps the readers a lot
ReplyDeleteHadoop Admin Online Training Bangalore
The article is very easy to under stand ios Online Training Bangalore
ReplyDeleteIt's a wonderful post and very helpful, thanks for all this information. You are including better information regarding this topic in an effective way.Thank you so much.
ReplyDeleteAllergy Medicines
Ayurvedic Medicine For Immunity
Hyperpigmentation cream
Viral Fever Medicines
Hi
ReplyDeleteTruly pleasant data here about by picking with the features. We need to make the perusers whether it is important for their pursuits or not. They will choose by taking a gander at the feature itself. I concur with your focuses yet I can't comprehend what's rationale behind by incorporating with the number? Why a large portion of the advertisers will propose that one? Is there any critical factor inside that please pass on me..! Big data
Regards,
Trep Helix
hanks for good info Hadoop Admin Online Training Bangalore
ReplyDeleteThanks for good info
ReplyDeleteHadoop Admin Online Course
Great Information you are shared with us. check it once through MSBI Online Training Hyderabad
ReplyDeleteGreat information thanks a lot for the detailed articleThat is very interesting I love reading and I am always searching for informative information like this.
ReplyDeleteRPA Training in Hyderabad
nice information!
ReplyDeleteThis blog was very useful for me waiting for more blog.
SAP FICO Training in Chennai
This comment has been removed by the author.
ReplyDeleteGood information. Thanks for sharing...
ReplyDeleteSAP MM Training in Chennai
Thanks for the great info you can also check the data below
ReplyDeleteHadoop
Hadoop online training
Really nice blog post.provided a helpful information.I hope that you will post more updates like thisHadoop Administration Online Training India
ReplyDeletethanks for sharing such details about big data and hadoop. Hadoop Admin Online Course Bangalore
ReplyDeleteThanks for helping me to understand basic Hadoop Mapreduce concepts. As a beginner in Hadoop your post help me a lot.
ReplyDeleteHadoop Training in Velachery | Hadoop Training .
Hadoop Training in Chennai | Hadoop
good blog,keep update...Hadoop training in Hyderabad!
ReplyDeleteHadoop training in Madhapur!
Hadoop training in India!
Nice post ! Thanks for sharing valuable information with us. Keep sharing..Hadoop Administartion Online Training
ReplyDeleteIt helps me a lot to learn about and clarify my doubts such a great help.Thanks for sharing the post.Here iam sharing the information that will help to progressive Data Management & Email Marketing Support For your Business.B2B Mailing List
ReplyDeleteThis really has covered a great insight on Hadoop. I found myself lucky to visit your page and came across this insightful read on Hadoop tutorial. Please allow me to share similar work on Hadoop training course . Watch and gain knowledge today.https://www.youtube.com/watch?v=1jMR4cHBwZE
ReplyDelete
ReplyDeleteWebtrackker is one only IT company who will provide you best class training with real time working on marketing from last 4 to 8 Years Experience Employee. We make you like a strong technically sound employee with our best class training.
Best SAS Training Institute in delhi
SAS Training in Delhi
SAS Training center in Delhi
Best Sap Training Institute in delhi
Best Sap Training center in delhi
Sap Training in delhi
Best Software Testing Training Institute in delhi
Software Testing Training in delhi
Software Testing Training center in delhi
Best Salesforce Training Institute in delhi
Salesforce Training in delhi
Salesforce Training center in delhi
Best Python Training Institute in delhi
Python Training in delhi
Best Python Training center in delhi
Best Android Training Institute In delhi
Android Training In delhi
best Android Training center In delhi
really Good blog post.provided a helpful information.I hope that you will post more updates like thisBig data hadoop online training Hyderabad
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteNice
ReplyDeleteBest Big Data and Hadoop Training in Bangalore
Mastering Machine Learning
Artificial intelligence training in Bangalore
AWS Training in Bangalore
Blockchain training in bangalore
Python Training in Bangalore
Most companies are looking for Hadoop professionals and offering good packages. Learn hadoop by joining in good training institutes with experienced trainers for Hadoop training in Hyderabad. Join now.
ReplyDeleteNice Information. Thanks for sharing about Hadoop & Bigdata
ReplyDeletemulesoft training
Nice codes. Helpful and thanks for the share. Keep up your good work. Thank you. :)
ReplyDeleteLED LCD TV Repairing Course in Delhi
LED LCD Smart TV Repairing Course in Delhi
LED Smart TV Repairing Course in Delhi
Mobile Repairing Institute in Delhi
Mobile Repairing Course in Laxmi Nagar
Mobile Repairing Institute in Laxmi Nagar
LED LCD TV Repairing Institute in Delhi
Computer Hardware Repairing Course in Delhi
Mobile Repairing Course in Delhi
Very nicely you have shared this blog with lot of good codes which I was really in need. Thanks for the share.. Keep it up. Thank you.
ReplyDeletemobile repairing course in delhi
mobile repairing institute in delhi
mobile repairing institute in laxmi nagar
led lcd smart tv repairing course in delhi
led lcd tv repairing course in delhi
led lcd tv repairing course in laxmi nagar
cctv repairing course in delhi
cctv repairing institute in delhi
laptop repairing course in delhi
laptop repairing institute in delhi
AC repairing course in delhi
AC repairing institute in delhi
Very nicely you have shared this blog with us. please keep sharing.
ReplyDeleteLed Lcd Smart Tv Repairing Course In Delhi
Led Lcd Smart Tv Repairing Institute In Delhi
Led Lcd Tv Repairing Course In Delhi
Led Lcd Tv Repairing Institute In Delhi
Led Lcd Tv Repairing Course In India
Mobile Repairing Course In Delhi
Mobile Repairing Institute In Delhi
Mobile Repairing Course In Laxmi nagar
Mobile Repairing Institute In Laxmi Nagar
Mobile Repairing Course In India
Thanks for posting such a great article.you done a great job to salesforce Online Training Bangalore
ReplyDelete
ReplyDeleteHi Your Blog is very nice!!
Get All Top Interview Questions and answers PHP, Magento, laravel,Java, Dot Net, Database, Sql, Mysql, Oracle, Angularjs, Vue Js, Express js, React Js,
Hadoop, Apache spark, Apache Scala, Tensorflow.
Mysql Interview Questions for Experienced
php interview questions for freshers
php interview questions for experienced
python interview questions for freshers
tally interview questions and answers
Nice blogs about Mastering Python With Mobile Testing at The
ReplyDeleteMastering Python With Mobile Testing training in bangalore
Thanks for sharing such a nice information on your blog on Hadoop Big Data Analytics. We all very happy check out your blog one of the informative and recommended blog. We are expecting more blogs from you.
ReplyDeletebig data training institutes in pune
big data institute in pune
big data institutes in pune
big data testing classes
big data testing
Hadoop is popular in the recent years and there are more job openings for Hadoop Developers. So many training institutes provide Hadoop training in Chennai. Learn and have a successful career.
ReplyDeleteHadoop is the most powerful keyword in the current IT world.There are so many institutes for Hadoop training in Hyderabad.For IT professionals plenty of opportunities it will suit for your best carrier
ReplyDeleteHire one of the best interior designers in Delhi NCR for your space. We don't build spaces, we transform them. We offers best quality interior designing services in affordable and reasonable prices. We As an interior designer know how to complete your project within your budget, time limit and with perfection.
ReplyDeleteSalon interior designers
ReplyDeleteWell done! It is so well written and interactive. Keep writing such brilliant piece of work. Glad i came across this post. Last night even i saw similar wonderful Python tutorial on youtube so you can check that too for more detailed knowledge on Python.https://www.youtube.com/watch?v=HcsvDObzW2U
Great post!! This can be one particular of the most useful blogs We’ve ever arrive across on this subject. Basically Wonderful. I am also a specialist in this topic so I can understand your hard work.
ReplyDeleteEconomics Journal
Journal Of Ecology
Thesis by publication
National Journal
Journal Of Information Technology
ReplyDeleteHi, thanks for sharing such an informative blog. I have read your blog and I gathered some needful information from your post. Keep update your blog. Awaiting for your next update.
sap abap online courses
I feel to a great degree sprightly to have seen your site page and foresee such countless the additionally captivating conditions scrutinizing here. Much valued once more for each one of the purposes of intrigue.
ReplyDeleteHadoop online training in Hyderabad
Bigdata Hadoop online training in Hyderabad
Custom eCommerce Web Design London UK, Hire Ecommerce Developers Lucknow India, eCommerce Website Development Services USA
ReplyDeleteVery knowledgeable post thank you for sharing Python Online Training Bangalore
ReplyDeleteNice blog...very useful information..thanks for sharing...
ReplyDeletepython online training in hyderabad
Random subset in mapreduce. I like your work.. Keep it up like this way..
ReplyDeleteVaastu consultant Vaastu consultant in India
Vaastu consultant in Delhi
Vaastu consultant in Delhi ncr
Vaastu consultant in East Delhi
Vaastu consultant in South Delhi
Vaastu consultant in Noida
Vaastu consultant in Ghaziabad
Vaastu consultant in Gurgaon Guru gram
Vaastu consultant in Faridabad
Vaastu Expert
Vaastu Expert in India
Vaastu Expert in delhi
Nice Article Very Helpful ! Thanks for sharing ! Also check
ReplyDeleteTutuapp APK
nice post...SAP BUSINESS ONE for Dhall solution
ReplyDeleteERP for food processing solutions
ERP for masala solution
SAP BUSINESS ONE for masala solution
ERP for Rice mill solution
Nice blog it is informative thank you for sharing iOS App Development Online Course Bangalore
ReplyDeletevery good post.
ReplyDeletePest control Services for Mosquitoes
Commercial Pest control services
It was really a nice post and i was really impressed by reading this
ReplyDeleteBig Data Hadoop Online Course
Its really an Excellent post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog. Thanks for sharing....
ReplyDeleteSolar Rooftop
Solar Water Heater
Solar Panel
Solar Module
Energy Efficient
BLDC Fan
Solar Power
Power Plant
Solar Training
Solar Pump
Thank you for an additional great post. Exactly where else could anybody get that kind of facts in this kind of a ideal way of writing? I have a presentation next week, and I’m around the appear for this kind of data.
ReplyDeleteClick here:
Microsoft azure training in btm
Click here:
Microsoft azure training in rajajinagar
Your site is amazing and your blogs are informative and knlowledgeble to my websites.This is one of the best tips in my life.I have in quite some time.Nicely written and great info.Thanks to share the more informations.
ReplyDeleteSeo Experts
Seo Company
Web Designing Company
Digital Marketing
Web Development Company
Apps Development
This looks absolutely perfect. All these tiny details are made with lot of background knowledge. I like it a lot.
ReplyDeleteBlueprism training in Chennai
Blueprism training in Bangalore
Blueprism training in Pune
Blueprism online training
Blueprism training in tambaram
The knowledge of technology you have been sharing thorough this post is very much helpful to develop new idea. here by i also want to share this.
ReplyDeleteDevops training in sholinganallur
ReplyDeletesuch a wonderful article...very interesting to read ....thanks for sharining .............
Data Science online training in Hyderabad
Hadoop online training in Hyderabad
Hadoop training in Hyderabad
Bigdata Hadoop training in Hyderabad
interesting blog, here lot of valuable information is available, it is very useful information. we offers this Big Data online training at low caste and with real time trainers. please visit our site for more details Big Data training
ReplyDeleteVery Interesting and wonderful information keep sharing this post kindly check
ReplyDeleteanime apps
I appreciate that you produced this wonderful article to help us get more knowledge about this topic. I know, it is not an easy task to write such a big article in one day, I've tried that and I've failed. But, here you are, trying the big task and finishing it off and getting good comments and ratings. That is one hell of a job done!
ReplyDeletejava training in tambaram | java training in velachery
java training in omr | oracle training in chennai
ReplyDeleteWhoa! I’m enjoying the template/theme of this website. It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between superb usability and visual appeal. I must say you’ve done a very good job with this.
Selenium Interview Questions and Answers
Best Selenium Training in Chennai | Selenium Training Institute in Chennai | Besant Technologies
Selenium Training in Bangalore | Best Selenium Training in Bangalore
Free Selenium Tutorial |Selenium Webdriver Tutorial |For Beginners
ReplyDeleteI have read your blog its very attractive and impressive. I like it your blog.
DevOps course in Marathahalli Bangalore | Python course in Marathahalli Bangalore | Power Bi course in Marathahalli Bangalore
Thanks for posting this info. I just want to let you know that I just check out your site and I find it very interesting and informative. I can't wait to read lots of your posts
ReplyDeleteangularjs Training in chennai
angularjs Training in chennai
angularjs-Training in tambaram
angularjs-Training in sholinganallur
angularjs-Training in velachery
This comment has been removed by the author.
ReplyDeletePiqotech is more efficient in executing administrative activities. Properties available, property tenants, air conditioning & other pieces of equipment are inspected, repaired and maintained correctly.
ReplyDeleteFacility Management System in India
Facility Management Softwares in India
Maintenance Management System in India
Maintenance Management Softwares in India
I have read your blog its very attractive and impressive. I like it your blog.
ReplyDeletePython training in marathahalli bangalore | Best aws training in marathahalli bangalore | Best Devops training in marathahalli bangalore
ielts coaching in gurgaon
ReplyDeleteAwesome..You have clearly explained …Its very useful for me to know about new things..Keep on blogging.
ReplyDeleteDevOps course in Marathahalli Bangalore | Python course in Marathahalli Bangalore | Power Bi course in Marathahalli Bangalore | Best Data Science Training in Marathahalli Bangalore | Deep Learning course in Marathahalli Bangalore | NLP course in Marathahalli Bangalore
Thanks for such a great article here. I was searching for something like this for quite a long time and at last I’ve found it on your blog. It was definitely interesting for me to read about their market situation nowadays. Well written article.Thank You Sharing with Us future of android development 2018 | android device manager location history
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteHey, Wow all the posts are very informative for the people who visit this site. Good work! We also have a Website. Please feel free to visit our site. Thank you for sharing.
ReplyDeleteWell written article.Thank You Sharing with Us angular 7 training in velachery | Best angular training institute in chennai
The authorities will exhibit the best honor at the forthcoming 25th Annual Screen Actors Guild Awards.
ReplyDeleteSag Awards 2019 Live Stream
I have to thank for sharing this blog, really helpful to me.
ReplyDeleteData Science Certification in Chennai
Data Analytics Courses Chennai
AWS course in Chennai
DevOps course in Chennai
RPA courses in Chennai
Angular 5 Training in Chennai
I think things like this are really interesting. I absolutely love to find unique places like this. It really looks super creepy though!!Roles and reponsibilities of hadoop developer | hadoop developer skills Set | hadoop training course fees in chennai | Hadoop Training in Chennai Omr
ReplyDeleteNice blog..! I really loved reading through this article. Thanks for sharing such
ReplyDeletea amazing post with us and keep blogging...Well written article pmp training in chennai | pmp training institute in chennai | pmp training centers in chennai| pmp training in velachery | pmp training near me | pmp training courses online
This blog is great check it out
ReplyDeletewww.bisptrainings.com
Thank you for providing useful information and this is the best article blog for the students.learn Oracle Fusion Technical Online Training.
ReplyDeleteOracle Fusion Technical Online Training
Thank you for sharing such a valuable article with good information containing in this blog.learn Oracle Fusion SCM Online Training.
ReplyDeleteOracle Fusion SCM Online Training
Good blog
ReplyDeletebest android training center in Marathahalli
best android development institute in Marathahalli
android training institutes in Marathahalli
ios training in Marathahalli
android training in Marathahalli
mobile app development training in Marathahalli
Thanks for providing such a great information in the blog and also very helpful to all the students.
ReplyDeleteOracle Fusion HCM Online Training
Thank you for sharing such great information with us. I really appreciate everything that you’ve done here and am glad to know that you really care about the world that we live in
ReplyDeleteonline Python training
python training in chennai
What are tips for data science interviews?
ReplyDeleteBe confident! (I am not afraid of strong/confident - just the opposite!)
If you do not know the answer - I will appreciate you more if you would say: "I need to go back home and read about it more"
Creativity (open your mind) is the secrete ingredient to become a great Data Scientist, and not just "A Data Scientist".
Please make sure you are familiar with simple concepts in probability theory and linear algebra.
I hope I didn't reveal too many secrets, now try to make yourself familiar with these questions - and good luck in the interviews :) If you want more details to contact us: #Livewire-Velachery,#DataScienceTraininginChennai,#DataScienceTrainingInstituteinChennai,#TrainingInstituteinvelachery,#DataScience, 9384409662,
You have done a great job!!! by explore your knowledge with us.
ReplyDeleteselenium testing training in chennai
best selenium training center in chennai
Big Data Training in Chennai
best ios training in chennai
German Training Chennai
Best German Training in Chennai
German Language Classes in Tambaram
German Language Classes in Adyar
ReplyDeleteIf you live in Delhi and looking for a good and reliable vashikaran specialist in Delhi to solve all your life problems, then you are at right place.
love marriage specialist in delhi
vashikaran specialist in delhi
love vashikaran specialist molvi ji
get love back by vashikaran
black magic specialist in Delhi
husband wife problem solution
Thank you for taking the time to provide us with your valuable information. We strive to provide our candidates with excellent care and we take your comments to heart.As always, we appreciate your confidence and trust in us
ReplyDeleteJava training in Chennai | Java training in Omr
Oracle training in Chennai
Java training in Chennai | Java training in Annanagar
Java training in Chennai | Java training institute in Chennai | Java course in Chennai
Blog is really great!!! Thanks for the sharing…
ReplyDeleteAngularjs Training in Chennai
Angularjs Training in Bangalore
Angularjs course in Chennai
Angularjs Training Institute in Bangalore
You truly did more than visitors’ expectations. Thank you for rendering these helpful, trusted, edifying and also cool thoughts on the topic
ReplyDeleteoffshore safety course in chennai
Thanks for sharing useful information. Keep on posting......
ReplyDeleteClear explanation on mapreduce topic with example.
MapReduce is one of the sub topic and main concept in Hadoop Course.
Best Online jaspersoft Training
ReplyDeleteAmazing Post. The idea you have shared is very interesting. Waiting for your future postings.
Primavera Coaching in Chennai
Primavera Course
Primavera Training in Velachery
Primavera Training in Tambaram
Primavera Training in Adyar
IELTS coaching in Chennai
IELTS Training in Chennai
SAS Training in Chennai
SAS Course in Chennai
Nice article Thanks for sharing the informative blog.
ReplyDeleteredbeardpress
Technology
Nice post. By reading your blog, i get inspired and this provides some useful information. Thank you for posting this exclusive post for our vision....
ReplyDeletedata science online training
sas online training
linux online training
aws online training
testing tools online training
devops online training
salesforce online training
I appreciate your efforts because it conveys the message of what you are trying to say. It's a great skill to make even the person who doesn't know about the subject could able to understand the subject . Your blogs are understandable and also elaborately described. I hope to read more and more interesting articles from your blog. All the best.
ReplyDeleteJava training in Chennai
Java training in Bangalore
Thank you for allowing me to read it, welcome to the next in a recent article. And thanks for sharing the nice article, keep posting or updating news article.
ReplyDeleteData Science Course in Indira nagar
Data Science Course in btm layout
Python course in Kalyan nagar
Data Science course in Indira nagar
Data Science Course in Marathahalli
Data Science Course in BTM Layout
Very good tutorial about MapReduce
ReplyDeleteBest choice to learn MapReduce
i'm Here to learn DevOps, Thanks For Sharing
ReplyDeleteDevOps Training in Hyderabad
DevOps Training in Ameerpet
DevOps Training institute in Hyderabad
Nice post. By reading your blog, i get inspired and this provides some useful information. Thank you for posting this exclusive post for our vision....
ReplyDeletevmware online training
tableau online training
qlikview online training
python online training
java online training
sql online training
cognos online training
HealRun is a health news blog we provide the latest news about health, Drugs and latest Diseases and conditions. We update our users with health tips and health products reviews. If you want to know any information about health or health product (Side Effects & Benefits) Feel Free To ask HealRun Support Team.
ReplyDeleteNice Information.
ReplyDeleteDigital Marketing Course in Hyderabad
Digital Marketing Training in Hyderabad
AWS Training in Hyderabad
Workday Training in Hyderabad
oracle course in delhi
ReplyDeletebest oracle training institute in delhi
oracle apps training in noida
oracle institute in noida
Excellent Article Thanks for Providing such a great information.
ReplyDeleteFeel free to have eagle eye look up of our website.
ielts coaching in Hyderabad
Machine Learning Course in Hyderabad
power bi training in hyderabad
python training in Hyderabad
I found your blog while searching for the updates, I am happy to be here. Very useful content and also easily understandable providing.. Believe me I did wrote an post about tutorials for beginners with reference of your blog.
ReplyDeletebest rpa training in bangalore
rpa training in bangalore
rpa course in bangalore
RPA training in bangalore
rpa training in chennai
rpa online training
it is really explainable very well and i got more information from your blog.
ReplyDeleteshareplex training
sharepoint Training
Thanks for this great share.
ReplyDeleteDellboomi Training
Devops Training
Supplements For Fitness the product, individuals should remember to stay hydrated and not use the supplement too much for some success.When choosing a weight-loss supplement, most of us think that the main ingredients are the active .
ReplyDeleteSupplements For Fitness Remember that when you take any medication, supplement or herb you are placing a chemical in your body that will react with any other chemical that is already there. This means that even though you are taking a weight
ReplyDeletehttps://www.supplementsforfitness.com/
Supplements For Fitness loss supplement to help you lose weight, you will react with any other medication prescribed for other underlying medical conditions or any other over-the-counter medication you may be taking. For this reason, you should check with the pharmacist to determine if there are adverse side effects from taking medications together.
ReplyDeleteSupplements For Fitness change your lifestyle habits, improve your nutritional intake, and get away from old snack habits. Once you abandon the nutritional supplements, if you go back to your old habits, your weight will recover and you will probably gain even more.
ReplyDeleteThanks very nice by reading this article keep on posting new trend article
ReplyDeletehttps://www.slajobs.com/sql-server-dba-training-in-chennai/
Needed to compose you a very little word to thank you yet again regarding the nice suggestions you’ve contributed here
ReplyDeleteBest Tally Training Institute in delhi
Tally Guru & GST Law course in Delhi
Tally Pro & GST Law course in Delhi
pmkvy course in Delhi
Latest updation On GST for Tally in Delhi
CPA course in Delhi
ddu-gky
Pilpedia is supplying 100 percent original and accurate information at each moment of time around our site and merchandise, and the intent is to improve the usage of good and pure health supplement. For More Info please visit Pilpedia online store.
ReplyDelete
ReplyDeleteNice blog..! I really loved reading through this article. Thanks for sharing such
a amazing post with us and keep blogging...
Gmat coachining in hyderabad
Gmat coachining in kukatpally
Gmat coachining in Banjarahills
ReplyDeleteGreat article thank you.
Big Data Hadoop Training in Hyderabad
Data Science Course in Hyderabad
AngularJS Training in Hyderabad
Advanced Digital Marketing Training Institute in Hyderabad
nice article. thanks for sharing information
ReplyDeleteword press training in hyderabad
Digital Marketing Course in Vijayawada
aws online training
sap abap online training
awesome article thanks for sharing
ReplyDeletedevops online training
python online traning
power bi online traning
machine learning online course
awesome article thanks for sharing
ReplyDeletedevops online training
python online traning
power bi online traning
machine learning online course
Hi,your blog article is good one.Thankyou for sharing the knowledge
ReplyDeleteAWS Training in
Hyderabad
Digital
Marketing Training in Hyderabad
Big Data
Hadoop Training in Hyderabad
Digital Marketing
Course in Hyderabad
Very Informative, Thanks for Sharing.
ReplyDeleteDigital Marketing Courses in Hyderabad
SEO Training in Hyderabad Ameerpet
SAP ABAP Training Institute in Hyderabad
Salesforce CRM Training in Hyderabad
Usefull Article. Thanks for sharing info.
ReplyDeleteDigital Marketing training in Hyderabad
IELTS training
in hyderabad
sap sd online
training
sap fico online
training
Great Article. Thanks for sharing info.
ReplyDeleteDigital Marketing Course in Hyderabad
Top Digital Marketing Courses with the live projects by a real-time trainer
online Digital Marketing Courses in Hyderabad
SEO Training in Hyderabad
Great Article. Thanks for sharing info.
ReplyDeleteDigital Marketing Course in Hyderabad
Top Digital Marketing Courses with the live projects by a real-time trainer
online Digital Marketing Courses in Hyderabad
SEO Training in Hyderabad
Awesome post with interesting facts. Thanks for taking time to share this with us. Looking forward to learn more from you.
ReplyDeleteMicrosoft Dynamics CRM Training in Chennai
Microsoft Dynamics Training in Chennai
Tally Course in Chennai
Tally Classes in Chennai
Embedded System Course Chennai
Embedded Training in Chennai
Microsoft Dynamics CRM Training in Adyar
Microsoft Dynamics CRM Training in Porur
Welcome to my Traffic Ivy review. With Traffic Ivy, you’ll get real, actual… trackable, guaranteed clicks. Members will purchase ‘traffic points’ on the frontend product Traffic Ivy review
ReplyDeleteHi dear, This is a nice and valuable post thanks for this information!
ReplyDeleteDigital Marketing Course in Kolkata
Vital Keto : Vous devriez considérer ces avantages. Je peux rassembler il ya une bonne alternative à la perte de poids. Pour ceux qui ne comprennent pas ce que la perte de poids est, c'est tout en un mot. Je veux dire que c'était très impressionnant. Vous seriez décalés au nombre de coups chauds qui passent par leur vie sans un indice. J'ai été surpris de découvrir les pensées de prime relatives à la perte de poids. Dans cet article, je vais vous donner un exemple de ce que je parle concernant la perte de poids.
ReplyDeleteVisitez-nous : Vital Keto
Vous pouvez également visiter : bit.ly/2QNfWny
Goyal packers and movers in Panchkula is highly known for their professional and genuine packing and moving services. We are top leading and certified relocation services providers in Chandigarh deals all over India. To get more information, call us.
ReplyDeletePackers and movers in Chandigarh
Packers and movers in Panchkula
Packers and movers in Mohali
Packers and movers in Zirakpur
Packers and movers in Patiala
Packers and movers in Ambala
Packers and movers in Ambala cantt
Packers and movers in Pathankot
Packers and movers in Jalandhar
Packers and movers in Ludhiana
Packers and movers in Chandigarh
Packers and movers in Panchkula
Packers and movers in Mohali
thanks for Providing a Good Information
ReplyDeleteanyone want to learn advance devops tools or devops online training visit:
DevOps Training
DevOps Online Training
DevOps Training institute in
Hyderabad
DevOps Training in Ameerpet
I am definitely enjoying your website. You definitely have some great insight and great stories.
ReplyDeletePython Online certification training
python Training institute in Chennai
Python training institute in Bangalore
I prefer to study this kind of material. Nicely written information in this post, the quality of content is fine and the conclusion is lovely. Things are very open and intensely clear explanation of issues
ReplyDeletePython Online certification training
python Training institute in Chennai
Python training institute in Bangalore
I gathered lots of information from your blog and it helped me a lot. Keep posting more.
ReplyDeleteBlue Prism Training in Chennai
Blue Prism Training Institute in Chennai
UiPath Training in Chennai
Robotics Process Automation Training in Chennai
RPA Training in Chennai
Data Science Course in Chennai
Blue Prism Training in OMR
Blue Prism Training in Porur
Hi, Great.. Tutorial is just awesome..It is really helpful for a newbie like me.. I am a regular follower of your blog. Really very informative post you shared here. Kindly keep blogging.
ReplyDeleteData Science Training in Indira nagar
Data Science Training in btm layout
Data Science Training in Kalyan nagar
Data Science training in Indira nagar
Data science training in bangalore
Thanks to take time to share this article
ReplyDeletehttps://sugunapestcontrol.in/
It's a wonderful post and very helpful, thanks for this information. You are including better information regarding this topic in an effective way.
ReplyDeletehttp://pestrid.in/
Thanks for such a useful information in this blog.
ReplyDeletehttp://pestcontrol24x7.com/
Such an wonderful article and thanks for sharing useful information.
ReplyDeletehttp://pcpestcontrol.in/
I didn't have any knowledge about this but now i got some knowledge so keep on sharing such kind of an interesting articles.
ReplyDeletehttp://imayampestcontrol.com/
Very good to read thanks
ReplyDeleteselenium training institute in kk nagar
Hey nice to read this blog thanks for sharing \
ReplyDeleteselenium training institute chennai
Keto CLarity
ReplyDeleteI might want to make maximum use of weight loss. They did that with precision. There's a little hard work required. If you can't sit back and get a laugh out of weight loss then you are must be too wound up. In addition to that, weight loss is easy.
https://supplementsbook.org/clarity-keto/
Keto CLarity
ReplyDeleteThis essay might seem a bit haphazard at first to you. That's the whole kit and caboodle. Some nerds feel the answer may be yes. If this is you, it's time to begin something new. I'm not all that value conscious. Remember, "Nothing lasts forever." It was untainted by recent events. This is a memorable display. The effect will be even greater if it is focused on weight loss. I trust this is a successful analysis.
https://supplementsbook.org/clarity-keto/
I read this post two times, I like it so much, please try to keep posting & Let me introduce other material that may be good for our community.
ReplyDeleteAWS Training in Bangalore
AWS Training in pune
The best Article that I have never seen before with useful content and very informative.Thanks for sharing info.
ReplyDeletedata science online training
best data science online training
data science online training in Hyderabad
data science online training in india
Great Article. Thanks for sharing info.
ReplyDeleteCEH Training In Hyderbad
Great Article. Thanks for sharing info.
ReplyDeleteCEH Training In Hyderbad
this blog is diffrent......i like it,..........
ReplyDeletehrms software solutions in chennai
List Of ERP Software Companies in Chennai
hr payroll software in chennai
real time tracking software in chennai
sales pro crm software in chennai
ReplyDeleteNice observation and good article,thankyo for sharing your knowledge,keep posting such information that's helpful to others
Devops online training
Best Devops online training
Devops online training in Hyderabad
Devops online training in india
Its a wonderful post and very helpful, thanks for all this information. You are including better information.
ReplyDeleteBig Data Training in Gurgaon
Big Data Course in Gurgaon
Big Data Training institute in Gurgaon
Thanks for posting useful information.You have provided an nice article, Thank you very much for this one. And i hope this will be useful for many people.. and i am waiting for your next post keep on updating these kinds of knowledgeable things...Really it was an awesome article...very interesting to read..please sharing like this information......
ReplyDeletehonor service center in vadapalani
Outstanding blog thanks for sharing such wonderful blog with us ,after long time came across such knowlegeble blog. keep sharing such informative blog with us.
ReplyDeleteCheck out : machine learning training in chennai
top institutes for machine learning in chennai
machine learning certification in chennai
artificial intelligence and machine learning course in chennai
Thanks for sharing a useful information.. we have learnt so much information from your blog..... keep sharing
ReplyDeleteWorkday HCM Online Training
Oracle Fusion Financials Online Training
Oracle Fusion HCM Online Training
Oracle Fusion SCM Online Training
perfect ! good to see you sharing the information. we would like to hear more about your blog
ReplyDeletePMI Certification
I really loved reading through this article... Thanks for sharing such an amazing post with us and keep blogging...
ReplyDeleteHadoop Online Training
Datascience Online TRaining
Wow blog is very usefull
ReplyDeleteHadoop Online Training
Datascience Online TRaining
nice post. MOBILE APP DEVELOPMENT COMPANY IN NAGPUR
ReplyDeleteEnjoyed reading the article above, really explains everything in detail, the article is very interesting and effective. Thank you and good luck for the upcoming articles learn python training in Bangalore
ReplyDeleteReally awesome blog. Your blog is really useful for me
ReplyDeleteRegards,
best selenium training institute in chennai | selenium course in chennai
Awesome content.
ReplyDeleteselenium training in Bangalore
web development training in Bangalore
selenium training in Marathahalli
selenium training institute in Bangalore
best web development training in Bangalore
This blog is very attractive. It's used for improve myself. Really well post and keep posting.....
ReplyDeleteSelenium Training in Chennai | SeleniumTraining Institute in Chennai
Thanks for providing a useful article containing valuable information. start learning the best online software courses.
ReplyDeleteWorkday HCM Online Training
Thanking for providing amazing article the blog contains good information that is helpful and useful for everyone to learn online courses.
ReplyDeleteBig Data and Hadoop Training In Hyderabad
This is my 1st visit to your web... But I'm so impressed with your content. Good Job!
ReplyDeleteMicrosoft Azure online training
Selenium online training
Java online training
Python online training
uipath online training
ReplyDeleteVery enjoyable to visit this blog and find something exciting and amazing.Slowly Breaking Wolves Warm Spring Night
ReplyDeleteVery enjoyable to visit this blog and find something exciting and amazing.
WallFlowereds AnF
I really loved reading through this article... Thanks for sharing such an amazing post with us and keep blogging...
ReplyDeleteData Science Training in Hyderabad
Hadoop Training in Hyderabad
Excellent blog I visit this blog it's really awesome. The important thing is that in this blog content written clearly and understandable. The content of information is very informative.
ReplyDeleteOracle Fusion Financials Online Training
Oracle Fusion HCM Online Training
Oracle Fusion SCM Online Training
oracle Fusion Technical online training
I really loved reading through this article... Thanks for sharing such an amazing post with us and keep blogging...
ReplyDeleteData Science Training in Hyderabad
Hadoop Training in Hyderabad
I am really happy to read your hadoob blog. your blog is very good and informative for me.
ReplyDeleteYour blog contain lots of information. It's such a nice post. I found your blog through my friend if you want to know about more property related information please check out here. With the experience of over 3 decades, Agrawal Construction Company is the biggest and the best builders in bhopal and the trust holder of over 10000 families. Agrawal Construction Company Bhopal is serving society, building trust & quality with a commitment to cutting-edge design and technology. Agrawal Construction Company's vision is to 'building trust & quality' which extends to developing residential, commercial and township projects in all the directions of the beautiful City of Lakes Bhopal and hence it is among the top builders in Bhopal. Currently, it has four residential such as Sagar Pearl, Sagar Green Hills, Sagar Landmark and Sagar Eden Garden.